
By Paul Williams
Introduction
I designed an Augmented Reality (AR) CTF for an event for Leigh Hackspace CIC initially aimed at children, but open on the day to people of all ages. The CTF comprised of a web application as well as physical component.

The code for the web application is located on GitHub at the following URL https://github.com/leigh-hackspace/spooky_hunt.
When designing a CTF, several considerations must be made, such as technical capabilities of the target audience, and the difficulty of which flags (ghosts) can be obtained.
The objective of the “spooky hunt” CTF was to capture the flags (in this instance ghosts) by scanning QR codes that direct the user’s browser to specific URLs. These URLs identify the ghost and allow the player to capture these ghosts by using information about the ghost and the player to create an association or relationship (which we will refer to as captures).

Considerations
Predictable Resource Identifiers
The basic URL for each of the ghosts is as comprised of the `<root_url>`/ghost/`<ghost_id>`. Where `root_url` is the address where the application is currently being served from and the `ghost_id` is the unique identifier for each individual ghost.
When adding new ghosts to the application, the database by default uses a sequential ID for the ghosts; meaning that it would be trivial to discern the identifiers after finding a small number of ghosts.
For example, if a user found ghosts 3, 4, and 5 they might reasonably infer that the IDs are sequential and then try other ids (such as /ghost/6, ghost/6 etc.) allowing them to capture all the ghosts in a short space of time.
Predictable resource identifiers can be identified by using a process known as fuzzing. An attacker could use a tool to automate the process of guessing correct ghosts by iterating through a list and sending many requests in rapid succession.
This can be mitigated in several ways, such as rate limiting request to the webserver or not using predictable unique identifiers. In the application, I opted to employ the latter.
This was achieved by adding a UUIDv4 unique identifier as an additional field when saving the new ghosts into the database and using that field as the resource identifier as opposed to the sequential id that the database records use by default.
This was achieved by adding the following code to the ghost model:
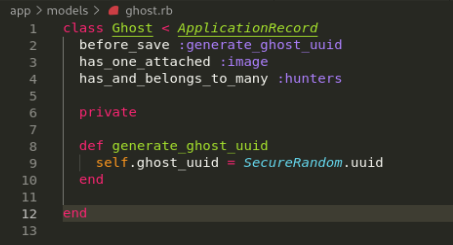
This results in randomly generated IDs that, although possible to fuzz would be extremely unlikely, as seen below:
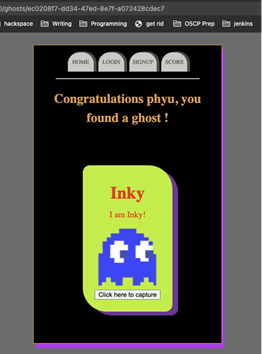
Using UUIDs in this way prevents an attacker from finding all the ghosts in a short space of time by simply guessing their IDs.
Insecure Direct Object References (IDOR)
As mentioned previously the application makes use of UUIDs when referencing objects such as ghosts and hunters, which increases the difficulty of exploiting an IDOR vulnerability. That said an attacker who knew both a valid hunter UUID and a ghost UUID could “capture” a ghost for another hunter. This was deemed an acceptable risk as the impact and risk of this happening is very low.
Code was also added to detect whether a hunter had a valid session when they found a ghost, which prevented errors that could disrupt the operation of the application (posting a capture without a valid hunter id could cause the application to “misbehave”). If a hunter finds a ghost but their session is no longer valid the application directs them to log in again. A rudimentary session token validation token was also added to the session variables when the user session was created, this token was an md5 hash of the hunter UUID and name, which if an attacker were find a hunter’s page via the uuid, unless this token matched what would be generated server side i.e. they had logged in, they would not see the user specific details and instead would be directed to a log in page to create the session.